Überprüfen Sie das Niveau Ihrer Texte. Ist ein Text A1, A2, B1 oder sogar höher? Der Language Level Evaluator (LLE Deutsch) analysiert das Sprachniveau eines Textes anhand von diversen messbaren Kriterien.
Sind Sie Sprachlehrer*in, Autor*in, Bildungsinstitut, Verlag oder andere Mitwirkende im Bereich DaF/DaZ? Möchten Sie mehr Objektivität in der Einschätzung bekommen, ob die Texte, die Sie nutzen, wirklich für das Sprachniveau Ihrer Lernenden geeignet sind? LLE Deutsch hilft Ihnen, das richtige Niveau Ihrer Texte schnell und zuversichtlich zu ermitteln. Probieren Sie es einfach kostenlos und unverbindlich für 14 Tage aus!
![]()
Nutzungsbedingungen
Bevor Sie LLE Deutsch nutzen können, werden Sie aufgefordert, unseren Nutzungsbedingungen zuzustimmen. Ohne Ihre Zustimmung kann der Registrierungsprozess nicht abgeschlossen werden.
LLE Deutsch Features
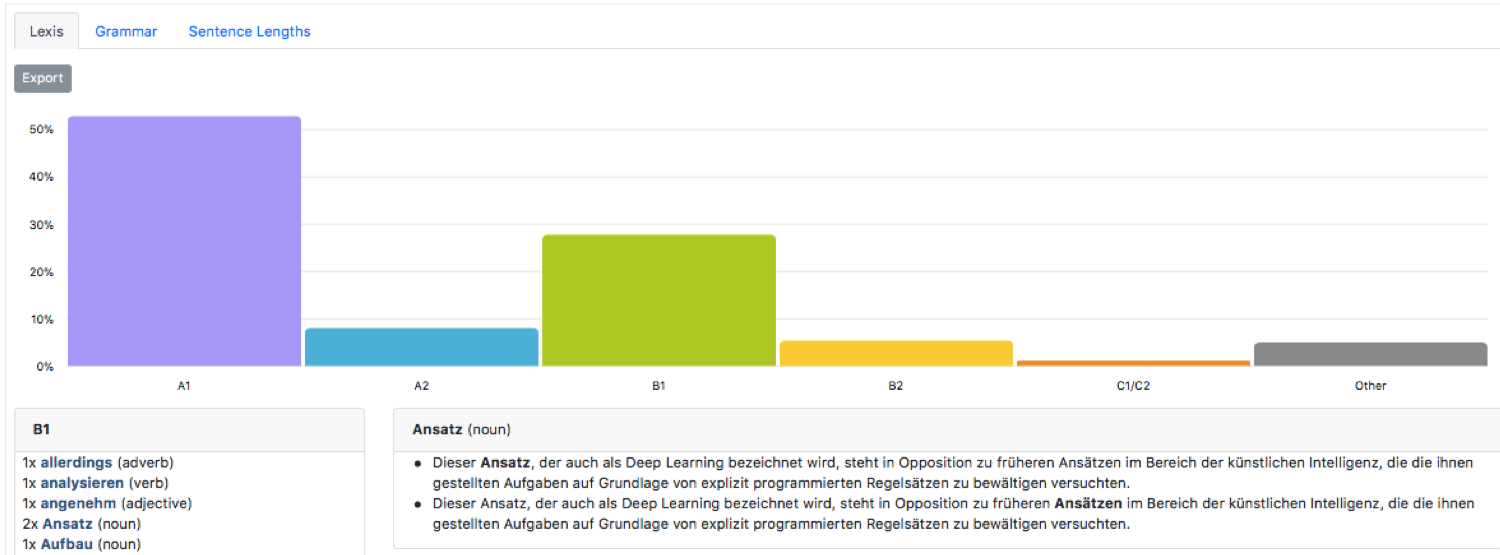 Beispiel einer Textanalyse mit LLE Deutsch: Wörter werden nach Lernniveau sortiert (A1-C2). Wenn Sie auf einen farbigen Balken klicken, sehen Sie die entsprechend zugeordneten Wörter. Wenn Sie dann auf ein Wort klicken, sehen Sie die Sätze, in denen es vorkommt. Hier: „Ansatz“.
Beispiel einer Textanalyse mit LLE Deutsch: Wörter werden nach Lernniveau sortiert (A1-C2). Wenn Sie auf einen farbigen Balken klicken, sehen Sie die entsprechend zugeordneten Wörter. Wenn Sie dann auf ein Wort klicken, sehen Sie die Sätze, in denen es vorkommt. Hier: „Ansatz“.
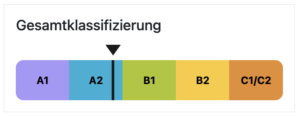
Beispiel einer Gesamtklassifizierung mit LLE Deutsch. Das GeR-Niveau (hier A2, aber fast B2) basiert auf maschinellem Lernen, das neben Lexik und Semantik eine Vielzahl weiterer Kriterien berücksichtigt.
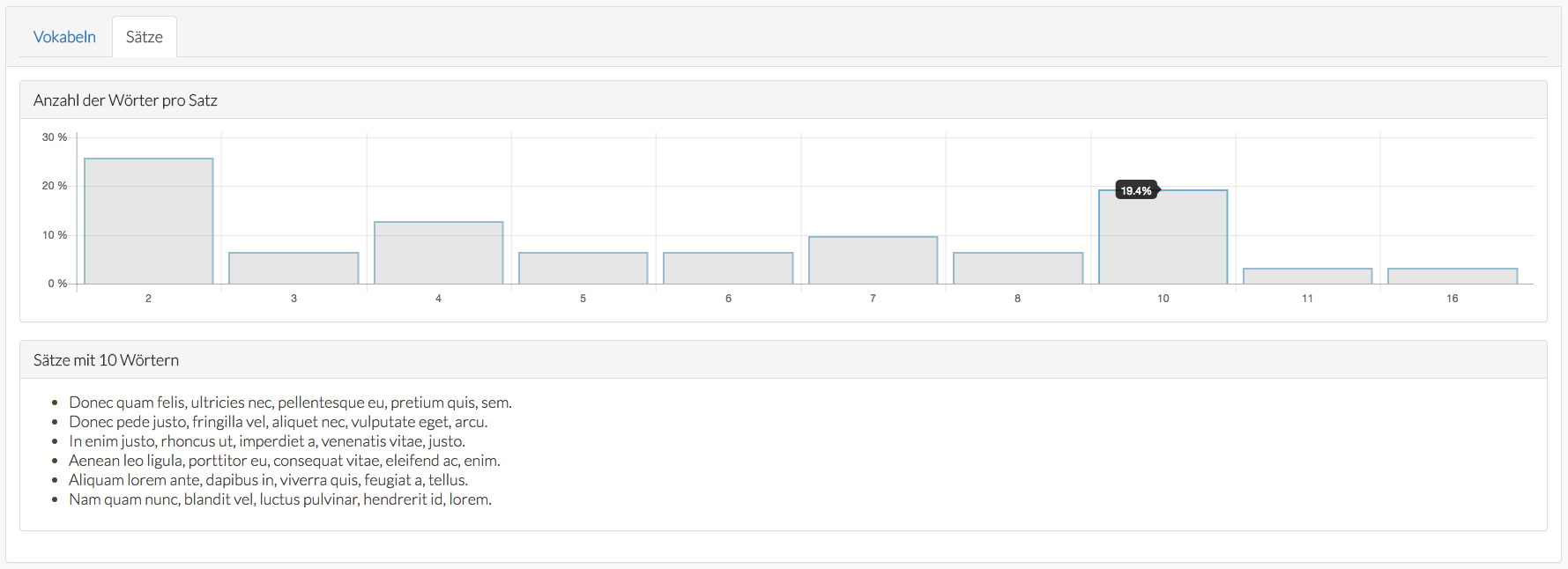 Beispiel einer semantischen Auswertung mit LLE Deutsch (Blindtext). Sie sehen die Anzahl der Sätze in dem Text, die Anzahl der Wörter pro Satz und die prozentuale Aufteilung aller Sätze nach ihrer Länge. Wenn Sie auf einen Balken klicken, sehen Sie die entsprechend zugeordneten Sätze. Hier ein Satz mit 10 Wörtern.
Beispiel einer semantischen Auswertung mit LLE Deutsch (Blindtext). Sie sehen die Anzahl der Sätze in dem Text, die Anzahl der Wörter pro Satz und die prozentuale Aufteilung aller Sätze nach ihrer Länge. Wenn Sie auf einen Balken klicken, sehen Sie die entsprechend zugeordneten Sätze. Hier ein Satz mit 10 Wörtern.
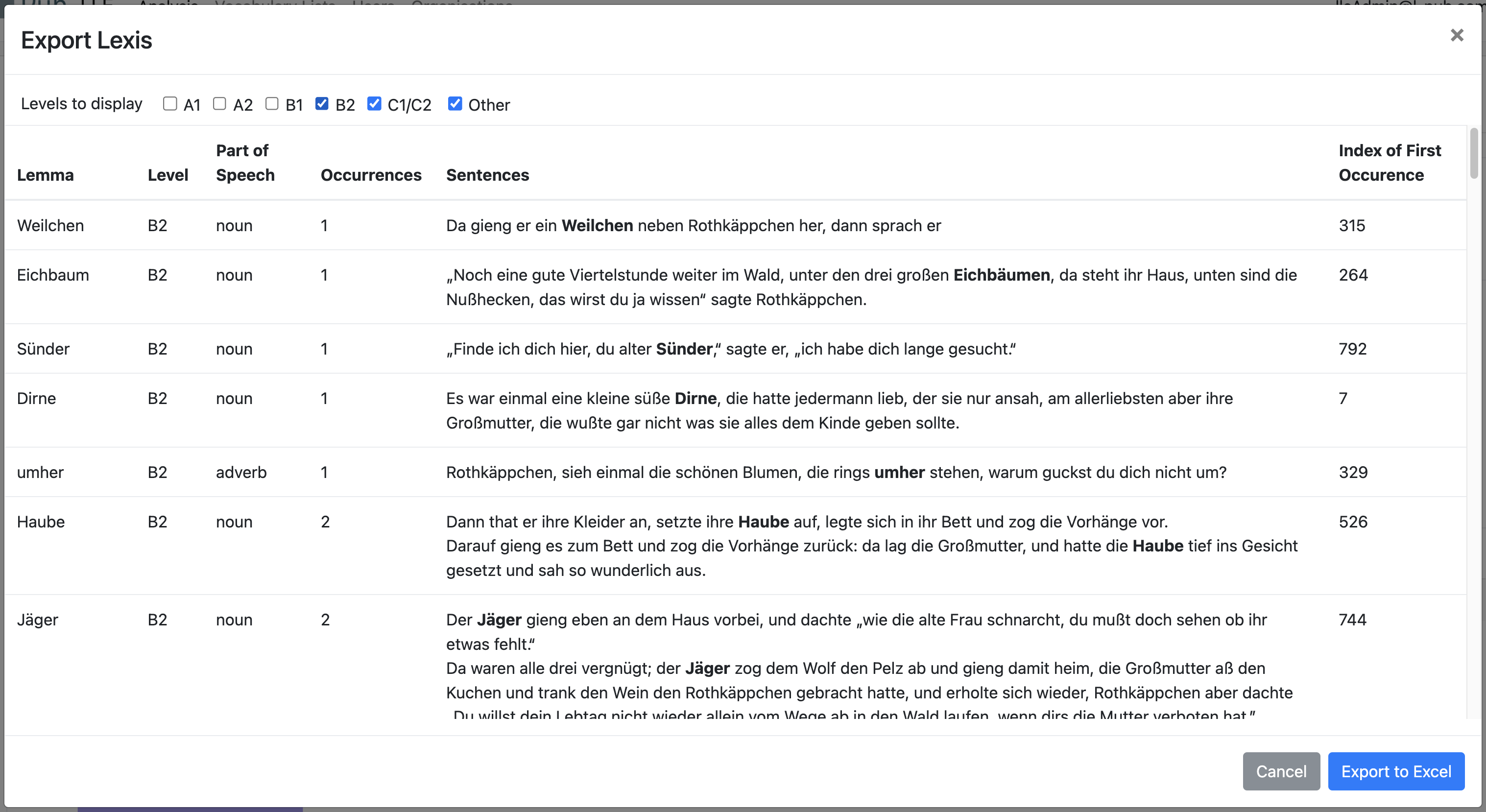 Beispiel für die Exportfunktion: Wählen Sie aus, welche Niveaus der Wörter für Sie relevant sind, und exportieren Sie die Liste als filterbare Excel-Datei. In diesem Beispiel werden die Niveaus B2 und aufwärts exportiert, z.B. um den Text für B1-Lernende vorzubereiten. Es geht um den historischen Text des Märchens „Rotkäppchen“ aus 1850.
Beispiel für die Exportfunktion: Wählen Sie aus, welche Niveaus der Wörter für Sie relevant sind, und exportieren Sie die Liste als filterbare Excel-Datei. In diesem Beispiel werden die Niveaus B2 und aufwärts exportiert, z.B. um den Text für B1-Lernende vorzubereiten. Es geht um den historischen Text des Märchens „Rotkäppchen“ aus 1850.
Was kostet LLE Deutsch?
Die Jahreslizenz für eine Person für LLE Deutsch kostet aktuell ca. €100 (der finale Preis hängt z. B. von Ihrem Land und den zu erwartenden Überweisungsgebühren ab). Die Lizenz erneuert sich nicht automatisch, also entscheiden Sie jedes Jahr, ob Sie mit dem LLE Deutsch zufrieden sind und weiter dafür bezahlen möchten. Die Lizenzgebühr deckt einerseits die Hosting- und Wartungskosten des LLE Deutsch, hilft uns aber auch, das Tool ständig weiterzuentwickeln und zu verbessern.
Möchten Sie eine Jahreslizenz für LLE Deutsch erwerben? Nutzen Sie bitte unser Bestellformular:
![]()
Für wen haben wir den Language Level Evaluator entwickelt?
Der LLE ist in erster Linie ein Hilfswerkzeug für die Auswahl geeigneter Lehrtexte und/oder ihre Optimierung für den Fremdsprachenerwerb. Wir haben unser Tool speziell entwickelt für:
- Verlage, die Sprachlernende als Zielgruppe haben und hierfür eine kompetente Einschätzung zum GeR-Lernniveau der Lektüren aus ihrem Programm benötigen.
- Lehrer*innen, die Fremdsprachen unterrichten und prüfen möchten, ob ihr selbsterstelltes Textmaterial zum Sprachlevel ihrer Schüler passt oder schnell Vokabellisten ausspielen möchten.
- Autor*innen, die ihre Texte für bestimmte Lernniveaustufen optimieren möchten und hierfür detaillierte Analyseergebnisse benötigen.
- Testersteller, die überprüfen möchten, ob ihre Inhalte einem bestimmten GeR-Lernniveau ausreichend entsprechen.
Danksagungen & Quellen
Der LLE wurde ermöglicht durch die Zusammenkunft verschiedener Spezialist*innen und Fachinformationen. Das Kernteam besteht aus Programmierer*innen, Sprachwissenschaftler*innen und Didaktiker*innen der Firmen L-Pub und Ernst Klett Sprachen sowie der Technischen Universität Darmstadt.
An dieser Stelle möchten wir die Personen und die benutzten Quellen vorstellen.

Das Team bei L-Pub
- David P. Steel (Konzept, Produktion, Vertrieb)
- Franck Valentin (Architektur, Programmierung)
- Battista Vailati (Programmierung)
- Leonore Kleinkauf (Projektmanagement)
- Vanessa Appoh (Sprachtechnologie, Didaktik, Einstufung nicht klassifizierter Vokabeln, Erstellung einer Übersicht zu Syntax und Morphologiebildung im Deutschen, Erstellung eines Korpus mit dazugehörigen Subkorpora, Erstellung von GeR-Vokabellisten aus verschiedenen Ressourcen)
- Miriam Hunter-Weinand (Korpusaufbereitung)
- Anette John (PR, Marketing)
Externe Beraterinnen
- Margret Rodi (Einstufung nicht klassifizierter Vokabeln, Erstellung von Kriterien für die Einstufung von Texten nach GeR, Ausbau/Anpassung der Vokabellisten nach A1-A2, Auswahl und Prüfung der Quellen, Gewichtung: Vokabel, Satzbau, Morphologie für die Sprachvermittlung)
- Kathrin Hein (sprachwissenschaftliche Beratung, Grammatikklassifikation, Systematisierung der Mehrwortlexeme)
Das Team bei Ernst Klett Sprachen
Folgende Mitarbeiter*innen der Ernst Klett Sprachen GmbH waren an der Entwicklung des LLE Deutsch beteiligt:
- Elizabeth Webster (Strategie, Vision)
- Hendrik Funke (Planung, Projektleitung)
- Sebastian Weber (Didaktische Leitung)
- Carina Janas (Redaktion)
- Arkadiusz Wrobel (Redaktion)
Das Team der Technischen Universität Darmstadt
Eine Zusammenarbeit mit dem Ubiquitous Knowledge Processing (UKP) Lab der TU Darmstadt wurde ermöglicht dank einer Förderung der Hessen Agentur (LOEWE 3-Programm). Folgende Personen der Universität waren in der Entwicklung des LLE involviert:
- Dr. Iryna Gurevych (Leitung des UKP Lab)
- Christian M. Meyer (Projektkoordination)
- Doktorand Ji-Ung Lee (Machine Learning, Deep Learning, Programmierung)
Vokabellisten
Der lexikalischen Einstufung des LLE Deutsch liegen Wortlisten aus Profile Deutsch und den Prüfungszielen A1-B2 zugrunde. Beide Listenquellen wurden gemeinsam vom Goethe-Institut und dem Österreichischen Sprachdiplom Deutsch erarbeitet. Wenn Texte Wörter aufweisen, die nicht in den oben genannten Listen enthalten waren, brachten die Teams von Ernst Klett Sprachen und L-Pub zusätzlich ihre Expertise ein, um eine adäquate Einstufung vorzunehmen. L-Pub setzt weiterhin Algorithmen ein, die zum Beispiel anhand von Wortlängen oder Wortbildungen GeR-Empfehlungen abgeben können.
Technologische Komponente
DKPro Core (ASL/GPL) Eckart de Castilho, R. and Gurevych, I. (2014). A broad-coverage collection of portable NLP components for building shareable analysis pipelines. In Proceedings of the Workshop on Open Infrastructures and Analysis Frameworks for HLT (OIAF4HLT) at COLING 2014, p 1-11, Dublin, Ireland.
Apache uimaFIT / UIMA Ogren, Philip and Bethard, Steven, Building Test Suites for UIMA Components; Proceedings of the Workshop on Software Engineering, Testing, and Quality Assurance for Natural Language Processing (SETQA-NLP 2009), June, 2009, Boulder, Colorado, Association for Computational Linguistics, pages 1-4 http://www.aclweb.org/anthology/W09-1501 https://uima.apache.org/uimafit.html https://uima.apache.org/index.html
Mate Tools Bernd Bohnet and Anders Björkelund; Tools for Natural Language Analysis, Generation and Machine Learning https://code.google.com/p/mate-tools/
The Stanford Parser http://nlp.stanford.edu/software/lex-parser.shtml
Staatliche Förderung
Unser großer Dank gilt an dieser Stelle der Hessen Agentur und dem LOEWE 3-Programm, die die Zusammenarbeit mit der TU Darmstadt in den Jahren 2017 bis 2019 ermöglicht haben.
![]()
![]()
![]()
Lesen Sie mehr über diese Förderung und das sogenannte a!-Projekt in Zusammenarbeit mit der TU Darmstadt und Ernst Klett Sprachen.
Lesen Sie mehr über den Stand der Entwicklung des LLE in 2018.
Die Anfänge des LLE-Projektes wurden zudem im Zeitraum 2013 bis 2015 durch eine lokale EFRE-Förderung über die Stadt Offenbach am Main unterstützt.

![]()


